
The Depth of Voice: Product Design Beyond Mature Technology
A while back, a PM colleague and I got into one of those conversations that just kept going. The topic was voice input, and we were both pretty fired up about it.
She mentioned she’d brought it up with a researcher on her team. The researcher basically shrugged — the tech is mature, it’s not that complicated, there’s nothing technically impressive about it anymore.
We both thought that was exactly the wrong way to look at it.

A technology being mature doesn’t mean the product has been figured out. If anything, I’d argue the opposite: a space where the underlying tech is already solved is where product thinking actually gets interesting. You’re not spending your energy on “can we build this” anymore. You can put everything into the harder questions — how deep can this go, how much smoother can the experience get, how close to zero can we push the friction of getting started.
Voice input is one of those spaces. The foundation has been there for a long time. But the real product potential? I think we’re still pretty early.

It started with the tape recorder
Voice input isn’t a new idea.
The earliest version was the voice recorder. Journalists would go record an interview, come back, play it back, type everything out word by word, then edit it into a story. The core logic was: capture first, convert later — and the conversion was entirely manual.

The traditional working method of a journalist
The need to turn speech into text has existed forever. It just used to require a human in the middle.
Things changed gradually. WeChat launched voice messaging in 2011, and it’s often cited as one of the key features behind its early growth — typing in Chinese on a phone keyboard was a pain, and sending voice was just faster. It worked. And it proved something more fundamental: for a lot of people, talking is the most natural way to express something.
WeChat eventually added voice-to-text, too. Hold the button, slide right, your words show up as text. Accurate enough, useful enough.
But I always had this uncomfortable feeling using it. Every time I tried to send a voice-to-text message, I’d catch myself stiffening up — speaking more carefully, more deliberately, because I knew every “um” and “like” and half-finished thought was going to be transcribed verbatim and handed to the person on the other end.
That tension is actually a real product problem.
Linear information vs. scannable information
To understand why, you have to think about how people actually receive information.
A 60-second voice message takes 60 seconds to listen to. There’s no way around it — the information is linear, it flows in one word at a time, you can’t skim it or jump to the part you care about.
The same content as text is different. Even if reading it carefully would take a minute, you can scan it in a few seconds and get the gist. The information goes from a line to a surface. You can take it in all at once.
So the “I hate long voice messages” thing isn’t really about being lazy. It’s about how eyes and ears process information differently — and eyes are just faster.

The reason why “I hate receiving long voice messages”
Converting speech to text solves the receiver’s problem. But if the output is a literal transcription of spoken language, the sender has a new problem: because casual speech is naturally messy, and once it’s written down, all the filler words and circular logic and unfinished sentences are right there on the screen. Which is exactly why you end up speaking more carefully, more formally — and that psychological overhead is what pushes the barrier back up.
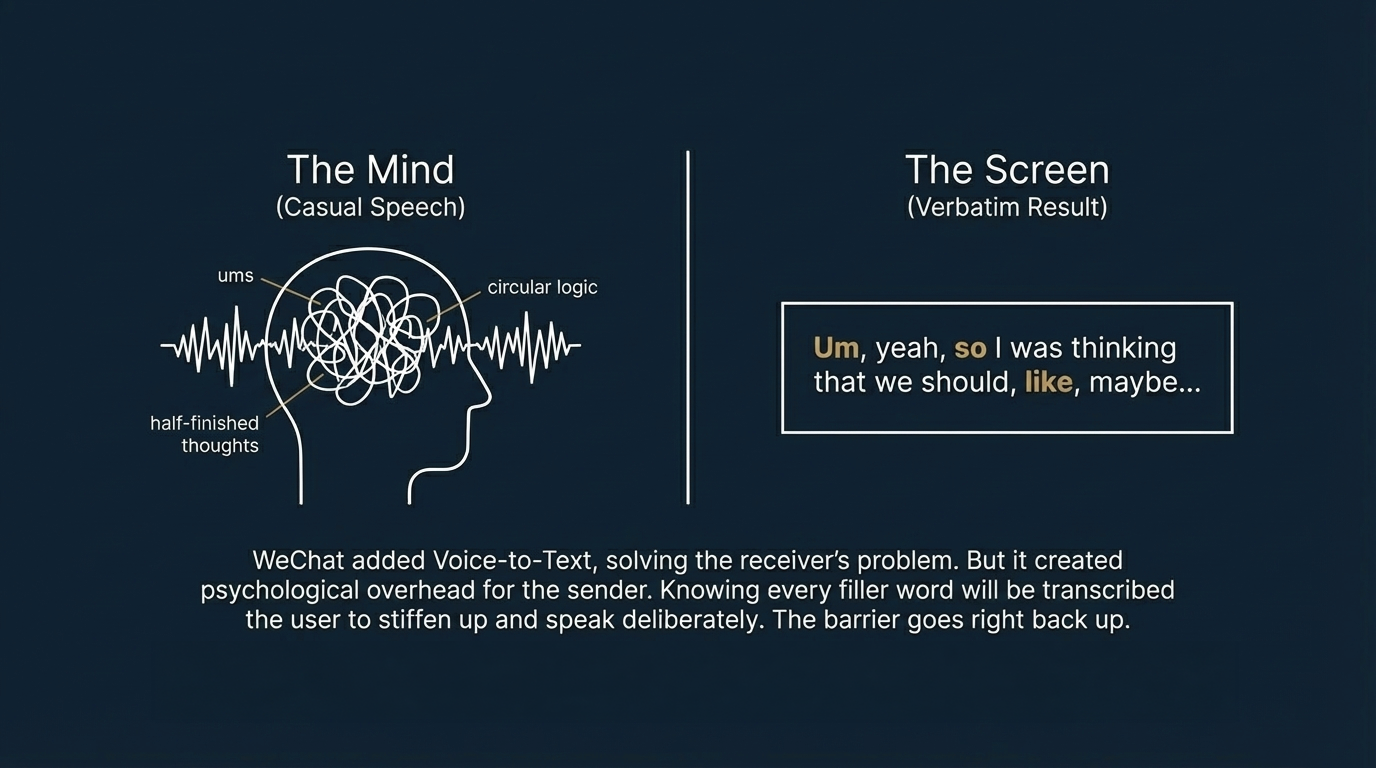
That’s the gap WeChat’s voice-to-text left open.
What Typeless gets right
Typeless opens with a line on their website: "The keyboard was a mistake." Their argument is that the keyboard was built for machines, not humans — and we just adapted to it for 150 years. Bold thing to put on a homepage. But it's not just attitude — the whole product is actually built around that premise.
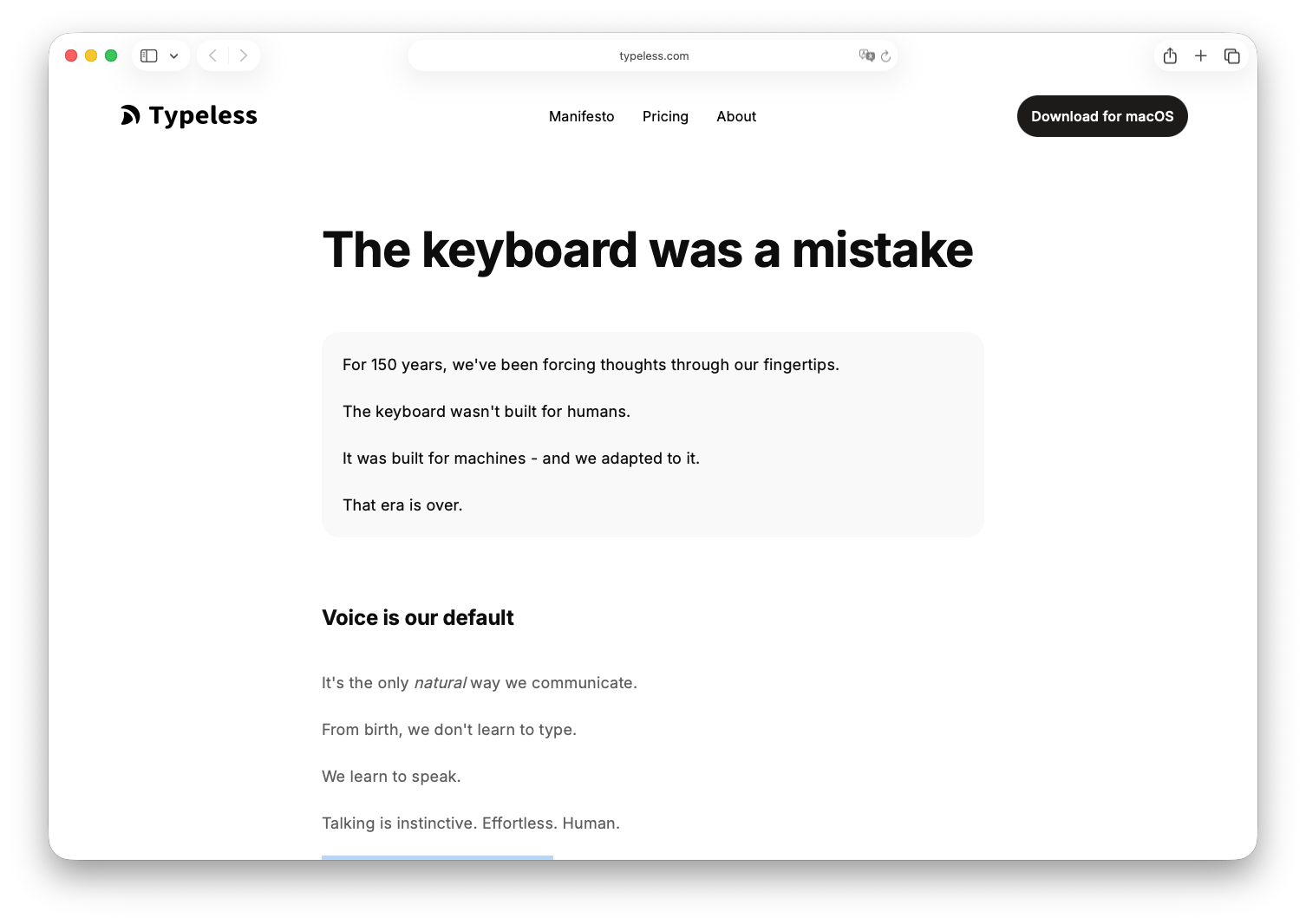
Which means its core logic is built around closing that gap: You no longer need to speak well. You just need to speak.
You can ramble, trail off, correct yourself mid-sentence — it doesn’t matter. What it does on the backend isn’t transcription, it’s comprehension. It takes whatever you said, messy and unpolished, and turns it into clean, readable prose.
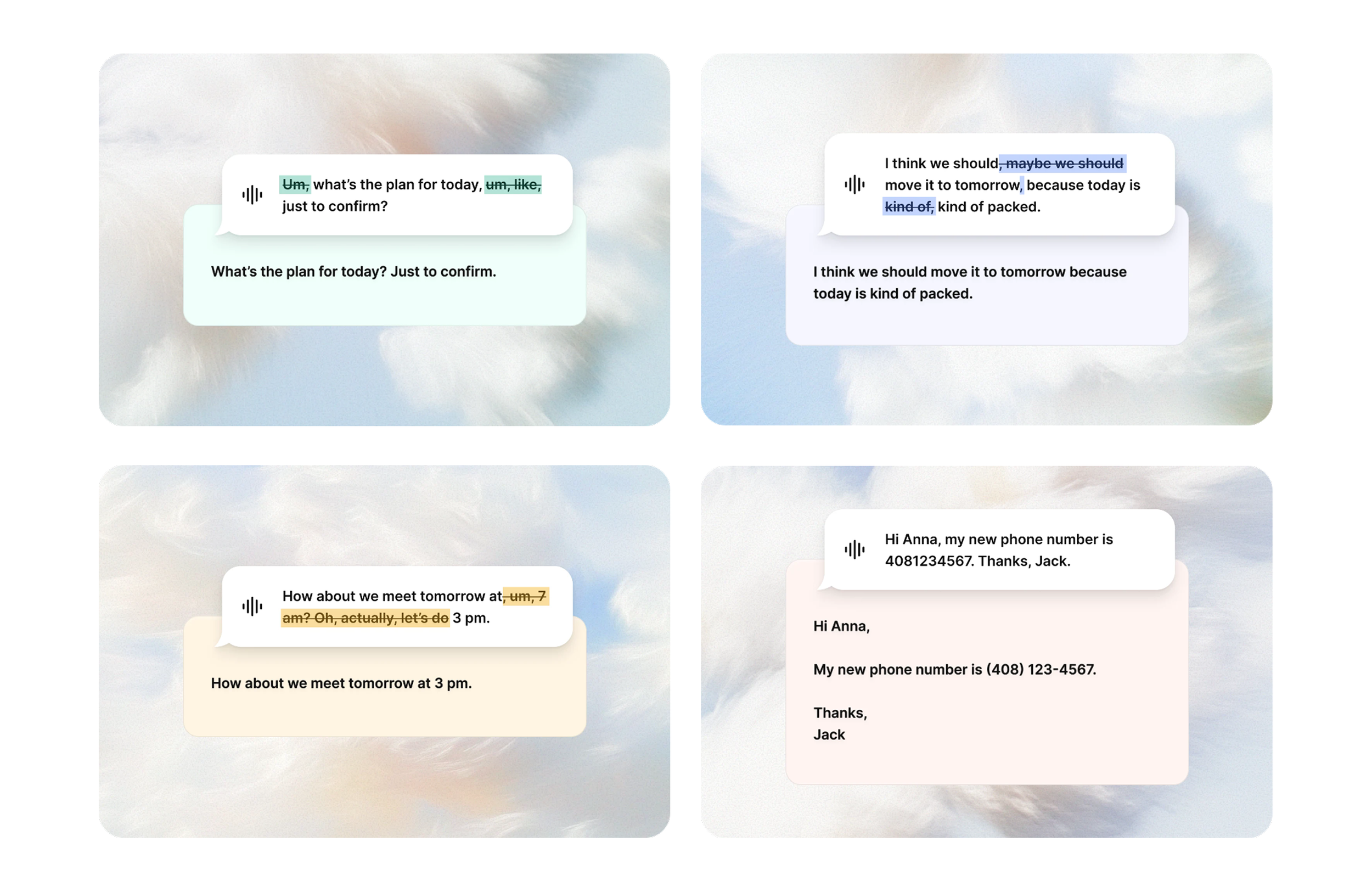
The person speaking gets to be free. The person reading gets something clear. Both ends served.
You no longer need to speak well. You just need to speak.
But the thing that really won me over was a single design decision: the keyboard shortcut to trigger voice input is the Fn key, bottom-left corner.
It makes sense once you think about it. Your right hand is usually on the mouse — it’s your dominant hand, and you don’t want to pull it away. The bottom-left corner is the easiest spot for your non-dominant hand to reach. And Fn doesn’t carry a lot of other function baggage. One press, recording starts.

One press, recording starts.
That’s it. One key choice, almost invisible as a decision, and the cost of starting to talk drops to basically nothing.
Then Typeless keeps going from there. Hold Fn + Shift and it converts what you say in Chinese directly into English output — language switching handled in the same gesture. Select a block of text, hold Fn, say “make this shorter” or “add something about X,” and it rewrites accordingly. You shift from speaking to directing, which is a whole different mode of working.
That’s what product thinking looks like in practice — taking one solid technical core and finding real use cases to extend into, each one removing an actual friction point from someone’s actual day.
PLAUD opened up a different kind of use case
If Typeless is mostly about communicating with other people, PLAUD solves something different: capturing things for yourself.
PLAUD is a wearable recording device — it comes as a small clip or a flat sticker that attaches magnetically to the back of your phone. The sticker version can detach and run independently, so you can carry it anywhere and record whenever.
I assumed the main use case was something like journaling or capturing random ideas. Then I accidentally recorded an onboarding meeting using PLAUD’s desktop app, and it completely reframed how I think about it.
After the meeting, it generated a structured infographic — broke the whole thing into four sections: core objectives, design principles, long-term goals, action items. It even pulled out who was responsible for what. My first reaction when I saw it was: this isn’t meeting notes. This is an actual handoff document.
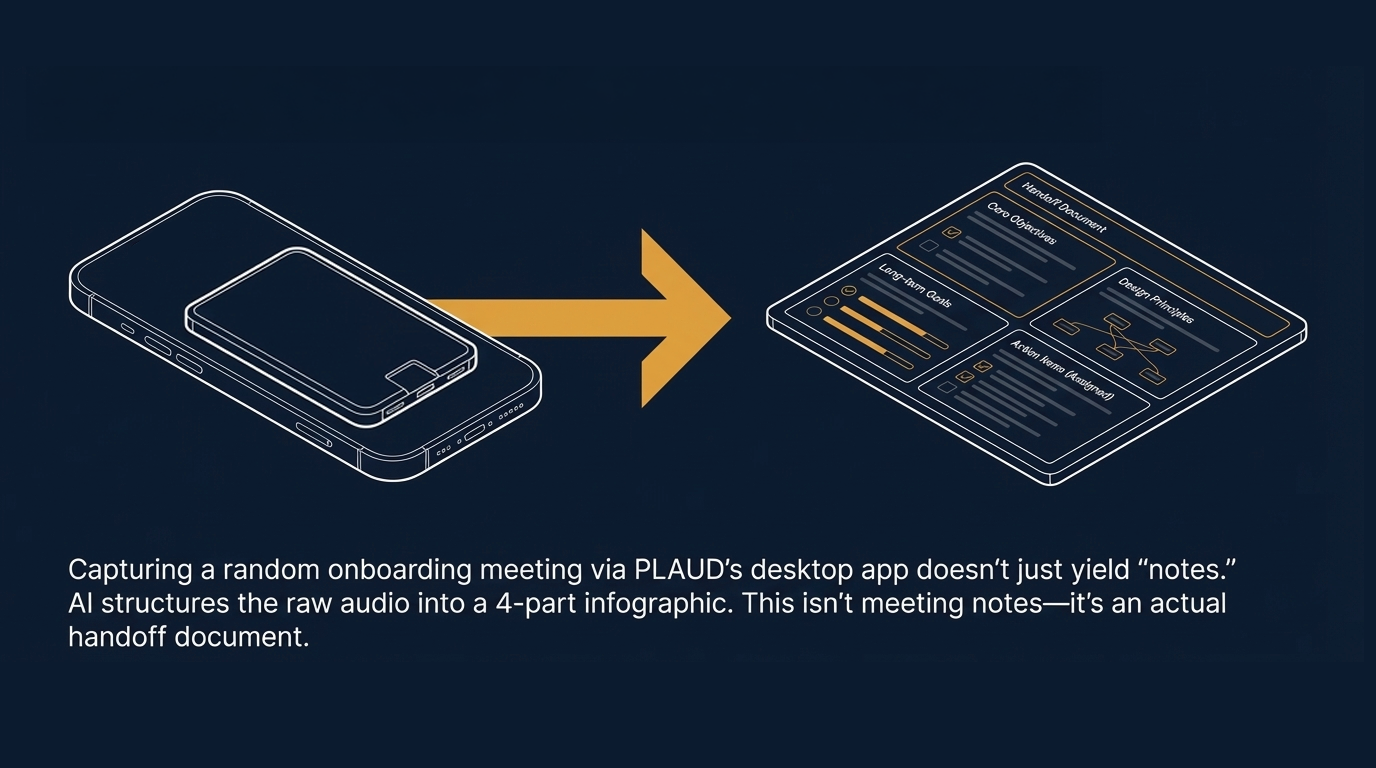
So I recalibrated. For professional use, meeting documentation might be the most immediately useful thing PLAUD does.
That said, it has some friction points that haven’t been fully worked out. When the sticker is detached from your phone and recording independently, there’s no status feedback on your phone screen — you genuinely can’t tell whether it’s recording or not, which creates this low-grade anxious feeling. And there’s a smaller but persistent annoyance: once the magnetic sticker is on the back of your phone, your MagSafe charger doesn’t attach anymore. Every time you charge, you have to peel the sticker off first.
That’s the kind of detail that probably causes users to quietly stop using a product, not with a dramatic moment, just gradually.
The gap between a good product and a great one often lives exactly there.
What AI actually changed
Back to the original question: voice input tech has been mature for years — so what does that mean?
The way I think about it now: a mature technology is the starting line for product work, not the finish line.
When the tech is still hard, most of the energy goes into making it work at all. There’s not much left over for experience details. But once the technical problem is solved, you can redirect everything toward the harder, more interesting questions — where exactly is the friction? How much lower can this barrier go? Does each new layer of functionality actually serve a real use case, or is it just feature accumulation?
AI pushed this whole space forward in a specific way. It gave all these mature technologies a new capability layer — voice recognition output isn’t just raw text anymore, it can be understood, reorganized, rewritten according to what you actually meant.

That’s what Typeless and PLAUD are really built on. The ability to capture voice has existed for a long time. The ability to take that capture and turn it into something genuinely useful to you — that became practical when AI arrived.
I pay for memberships to several voice products. Not because any of them do something technically special. But because they’ve taken the same underlying tech and built deep enough into real scenarios that the experience stops feeling like a tool and starts feeling like it just works.
Once you’ve had that, the products that built the feature but didn’t think through the experience feel like a step backward.
That’s the gap product depth creates.

Which gets me thinking about something bigger: if the barrier to capturing a thought can be brought down this low, what else might that change?
We’ve always treated recording things — ideas, observations, things that matter — as something you have to sit down and do deliberately. But if capturing and organizing can be separated, if one can happen in any moment and the other can happen later, maybe the whole habit looks different than we assumed.